Choosing a database: There’s more to life than SQL

Whether you’re building your first or your fiftieth application, choosing a database is one of the toughest choices to get right. It will be one of the first decisions you make, and will likely also be one that ingrains itself within your application. With a plethora of excellent databases available, and an overwhelming amount of information readily available, this only makes the task more difficult.
Our latest projects, and a desire to develop at pace here at Runa, have necessitated a shift to an event driven architecture, which opens up a lot of opportunities to leverage the latest technologies. For our most recent project, we’ve had to select a database for a system with multiple 3rd party integrations which would return varying metadata, capable of facilitating a high number of transactions.
In this post I’ll give a concise overview of the common database types, their uses, and a few of the considerations that should be made when selecting a database that are less commonly mentioned.
What are the main types of database?
Relational Databases
Examples: PostgreSQL, MySQL, Oracle DB
Relational databases are the most commonly used type of database. Data is organised in tables which, unsurprisingly, can have relations defined with each other using foreign keys. SQL allows you to query these tables and join them together, allowing you to efficiently retrieve data in a format that suits your requirement. Tables are structured using columns and rows, where columns define the data attributes and the rows define a record within the table.
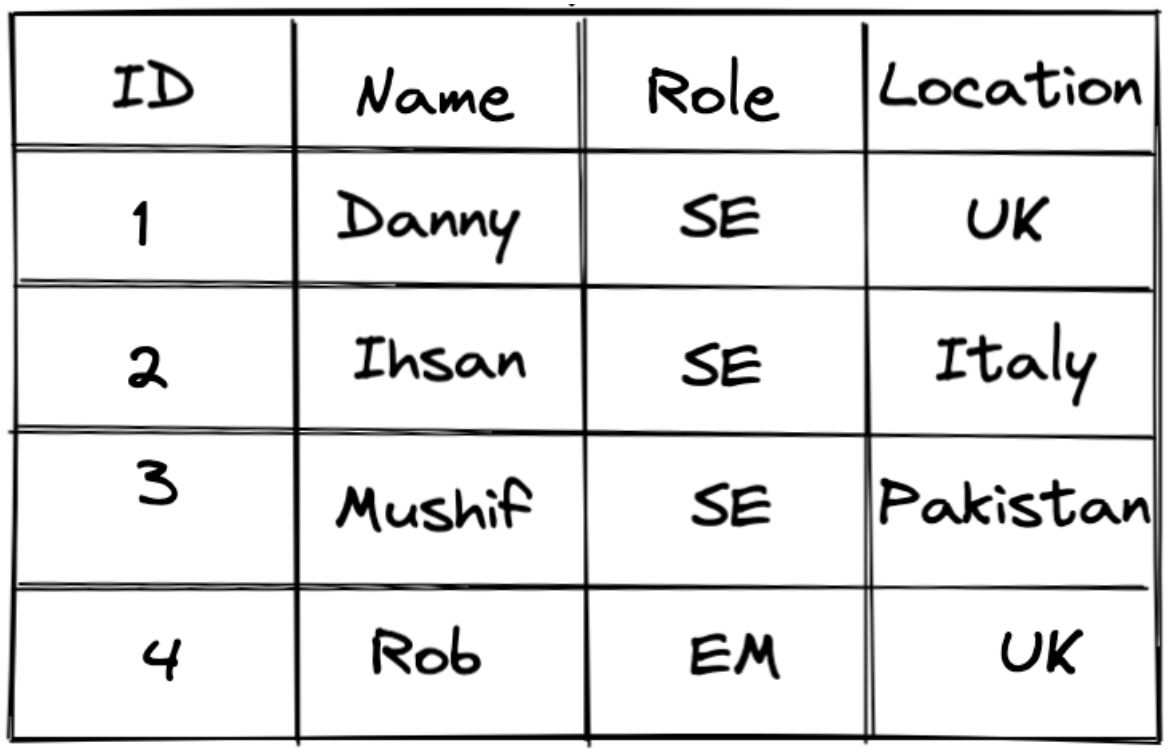
Figure 1: Example of a table in a relational database.
Relational databases ensure ACID transactions, which means data integrity is always preserved. ACID transactions, coupled with the need to define models prior to data insertion, means that relational databases are perfect for when the consistency and stability of the data is integral to the behaviour requirements. However, this stability comes at the cost of flexibility.
The main downfall of relational databases is the scalability of the performance when a high volume of transactions are required, or if the geolocation of the database is important. The typical first port of call used to scale relational databases is to scale vertically, adding more computing power. However, this of course has its limitations. Beyond this, the use of sharding, caching and read replicas would need to be introduced, but this results in extra work to tackle these issues, which are often only realised when it’s evident that the database has become the bottleneck.
The perfect use cases for relational databases are when the required data consistency is high, and relationships are well defined. A reporting system for an eCommerce platform where there are tables including customers, orders, payments and products would be a perfect candidate for a relational database. The reason being is that the relationships are well defined, the utilisation of transactions would be required, and the use of relationships to perform bespoke queries would be needed for any analytics or reporting. Another unspoken benefit of relational databases is the amount of documentation available which makes the development process easier.
Graph Databases
Examples: Amazon Neptune, Neo4j
Graph databases are defined using nodes — which define the data stored — and edges, which store the relationships between nodes. This storage of relationships means that joining these sets of data is extremely quick, in contrast, a relational database would compute these at query time, slowing down the entire process.
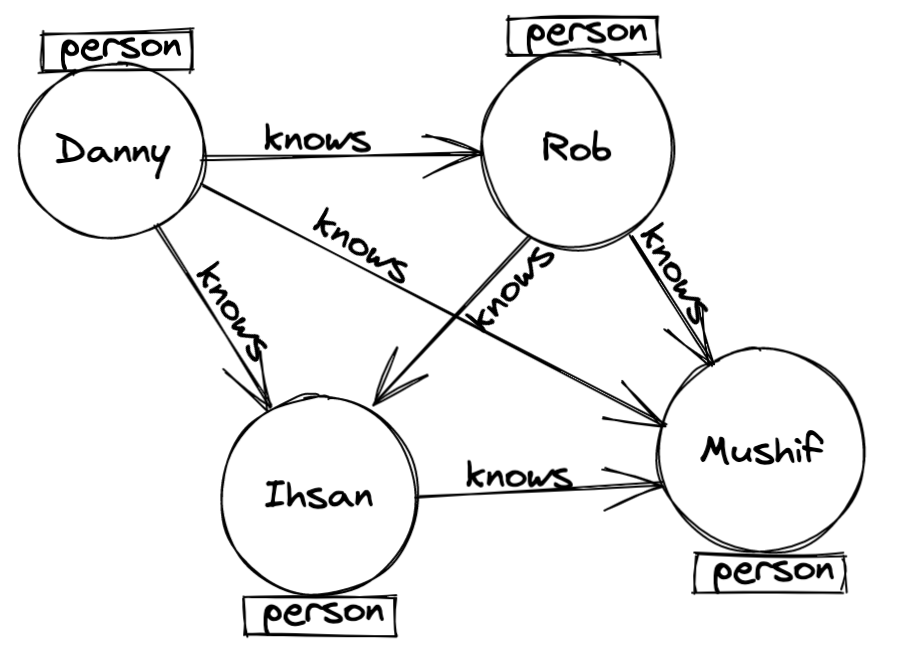
Figure 2: an example of a simplified graph database.
Utilising a graph database’s unique capabilities requires a querying language optimised to do so, which has resulted in a multitude of different query languages such as Cypher, SparQL and Gremlin. These querying languages employ pattern matching to extract data. For example, if I wanted to query who Rob knows directly, a query in could look like this;

Intuitively, graph databases are great for storing data on how things are connected to each other, for example friends on a social network, advertisement display or fraud prevention. Conversely they are less suitable for storing things such as transaction histories. The support for ACID transactions and the ability to scale varies between each database, so it’s worth researching this prior to selection.
Document Databases
Examples: MongoDB, CouchDB, ElasticSearch
Document databases typically store data as structured nested documents (think JSON/BSON, XML), meaning that they intuitively correspond to the objects in your code. These documents are stored in collections, and are analogous to a row and table in a relational database.

Figure 3: an example of a document.
The documents allow you to store semi-structured information using flexible schemas, allowing you to update due to changing requirements easily. In this respect, this is one of the main differences to relational databases which would require an SQL statement to update the schema. This flexibility makes document databases great for storing anything that will potentially have varying content, but you need flexible querying; think product information or customer details.
Most document databases support a join functionality in one form or another, however the way that documents are designed to be used, means that you typically shouldn’t. For example a customer and customer contact details would typically be stored in 2 separate tables in a relational database, however in a document database you would utilise the hierarchical structure to store them within a single document.
Most document databases also support ACID transactions, and typically support horizontal scaling; this scaling allows you to support huge volumes of read queries. MongoDB also supports strong consistency (linearizability), which is always handy.
Key / Value Databases
Examples: Redis, Berkeley DB
Key/value stores are the most conceptually simple of the databases; it is a non-relational database where values are stored against keys. These values can be as simple as a single piece of data, up to more complex objects, similar to documents. This sounds extremely similar to a document database, however in a key/value database, the information stored against the key is less transparent. This means that for a document database, you can query against non-primary keys, allowing for higher flexibility, whereas with a key/value database, you are typically limited to querying against a single primary key.
While there is a lower level of flexibility within key/value databases, this results in a better performance on reads and writes, so there are benefits too! They’re best used when you know what you want to query. Then, finding the information of a known key is extremely quick, however, if you need to filter by a non-primary key, this becomes more difficult.
The use cases for key/value databases are quite similar to document databases; user profiles, session data or simply caching data. As with document databases, they typically also support horizontal scaling.
Wide Column Databases
Examples: Apache Cassandra, Bigtable, ScyllaDB
When querying big data to generate analytics and reports, it’s rare that you wish to query every column of every row and quite inefficient to do so. Even when reducing the number of columns selected, this still can result in large volumes of unnecessary data being parsed! Wide column/column family databases, circumvent this issue by partitioning data in columns, and when it comes to querying, only the columns required are retrieved. The result of this is a sparse matrix of partitioned columns, containing a single data type (wide column), or column families which store a row, which in turn has nested columns and values within itself.
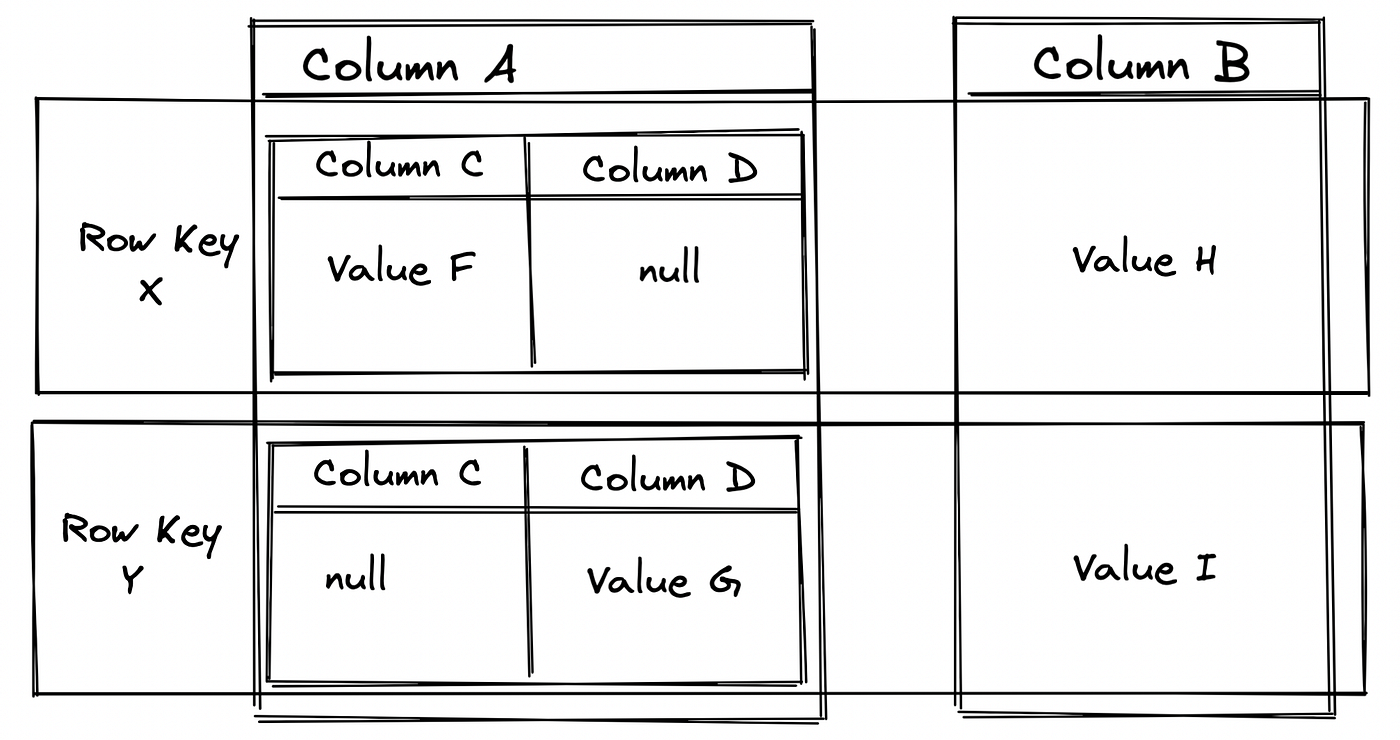
Figure 4: Example of a wide column/column family database structure.
Wide column databases are fantastic for things like data logging, reporting and even message services — Discord wrote a fantastic poston their migration from MongoDB to Apache Cassandra. Their best use cases are when you have predictable query patterns, high write, and lower read frequency requirements. The sparse matrix design allows for high flexibility within the database; a row doesn’t have to use all columns, meaning different rows can be composed of different columns.
Wide column databases typically trade off this high write speed with lower linearizability (due to the horizontal scaling), meaning that when you query, you are not guaranteed to get the latest write information.
. . .
Factors to consider when choosing a database
The C’s in CAP and ACID are very different and aren’t particularly important.
Two concepts I often see confused are the C’s in CAP and ACID; whilst both stand for consistency within these acronyms, they essentially mean two completely different things.
Starting with the C in ACID, consistency here means that certain constraints or statements about your data must always be adhered to; be this type, certain combinations, limitations or uniqueness. This, however, is the limitation of a database’s capabilities with regards to consistency — anything more complex cannot be handled by a database. Most databases offer this level of consistency by default and it cannot substitute the invariants produced by business logic, and subsequently cannot prevent a transaction that neglects these from being completed. Thus, in my opinion, atomicity, isolation and durability are more important traits offered by databases, and things you should value more highly.
Conversely, the C in CAP (see flaws of CAP in this great article), is better termed as linearizability, which can be simply broken down to mean: when a database is written to, any subsequent read will see the exact data that has just been written. As you can imagine in certain applications this is essential — for example checking a customer’s balance before an order, or the stock levels of a product.
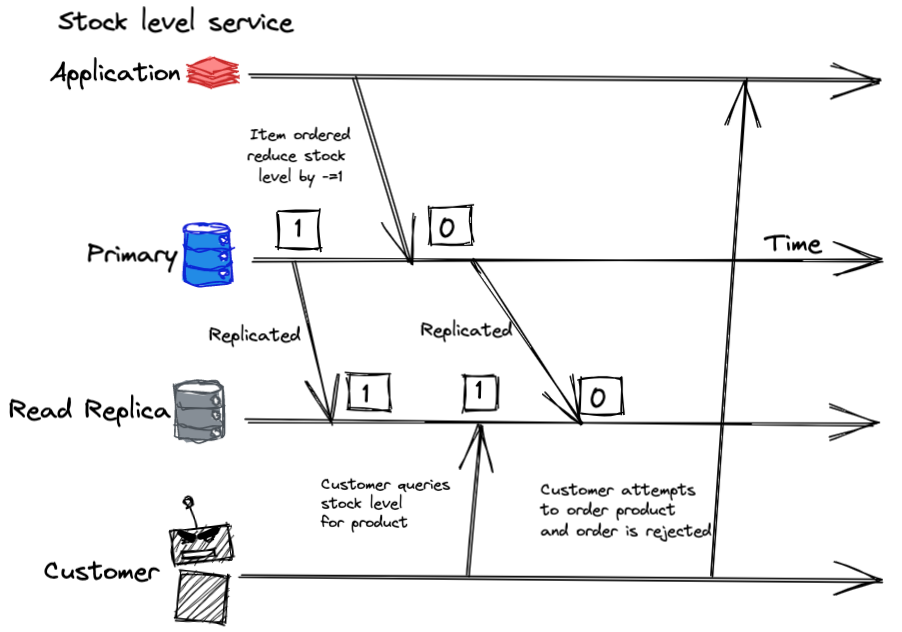
Figure 5: Example of how a lack of linearizability can impact application behaviour.
A lot of databases can offer linearizability despite having replicas, and while it’s not instantaneous, the latency between replication can be fast enough that it has no real-world implications for your application. Linearizability is also not an essential quality of a database and by sacrificing this you can gain in other areas, such as read and write speed. Examples of where high linearizability isn’t required could be a reporting system that aggregates the volume of orders made or how many users have liked a social media post — anything where the exact real time value isn’t required.
What kind of relationships are required?
When querying your data, what kind of relationships are required? In my opinion, this is one of the factors that differentiates the database types listed above the most; not SQL vs NOSQL. This question will largely depend on your application’s intended behaviour, and the architecture that it is constructed under.
There is no one-size-fits-all database for this, and nor should anyone be under the illusion that using a single database type is the only way to go; separate services may require completely different databases. When first deciding what database you wish to use, model your data — define entities and relationships and it will likely become clear which database is most suitable for you. It’s also pertinent to mention that having relationships is not a necessity, if you can structure your data in such a way that avoids these relationships it can benefit your application’s performance; relationships always have a cost.
Requirements – are they well known?
This question is quite broad and can mean a plethora of prerequisites, from functional to non-functional. There are countless possible requirements beyond application behaviour; are you locked into a cloud provider? Do you need a fully managed service? How important is security? All of these things would not be considered primary requirements that were in the previous sections, however they all play a large role within the dynamics of selection of a database.
When you consider options outside of your hosting ecosystem, you open yourself up to spending far more time than initially budgeted for, managing these solutions — security updates, failovers and back ups. These of course all play second fiddle to the primary requirements of a database and the capabilities they give you, however it is imperative to consider these factors to avoid headaches further down the road.
Conclusions: How did we navigate this wonderland?
These considerations, along with the desire in agile development to move fast and iterate quickly, mean that spending the time early in the development process will pay dividends – migrations at a later stage are costly and ideally avoided. This decision will not only impact the performance of your application, but also the development process.
The factors listed above are not the only ones to consider, they are the factors I believe to be frequently overlooked. I thoroughly recommend spending a large amount of time reviewing and testing as many options as possible to understand the fundamental differences between each of the choices available.
After going through this process ourselves, it was between a key/value and document hybrid database and a document database. We narrowed it down to being between DynamoDB andDocumentDB — a MongoDB fork by AWS.
Firstly, at Runa, our current infrastructure is all on AWS; we want a managed service that performs security updates, backups, and scaling. Both of these support strongly consistent reads, which is what we’ll need as part of this feature.
Finally, the schema flexibility is perfect for our requirements; we’ll be storing varying metadata from third-party providers, and the desire to have a good developer experience is high up on our list; not having to write schema migrations definitely helps achieve this. We’re going to spend some time experimenting with the two, and I’ll be sure to update this post when we reach a conclusion.
Check back soon to see which of the two options we went for!
Update
We went with DynamoDB for our choice of database. Whilst the schema flexibility certainly enabled us to move quickly, we did not account for all of the access patterns – access pattern flexibility is certainly the key weakness of DynamoDB. This required some careful tweaks to indexes, which cost us some time. In hindsight we should have planned for more access patterns. It’s always important to invest this time up front, however remaining flexible when curveballs come your way is vital.